After 3 years, 98 posts, and having amassed about 7,000 followers (according to WordPress’ stats), I’m idling this blog. All the articles will remain online. I just won’t be adding new content.
This may or may not be a permanent move. It depends on many things. But I’ll be too busy in 2015 to scribble down thoughts in this space.
You can keep up with me at the East Bay Express where I’ll be writing frequently, and you can follow me on Twitter, if you don’t already – @darwinbondgraha.
I will still be checking e-mails, if anyone wants to send me tips, anonymously, through the contact page on this blog.
The counties encompassing Silicon Valley and San Francisco are among the most unequal places in California and the entire United States, according to income tax statistics published by California’s Franchise Tax Board. The same data set shows that rural regions, the major population centers of the Central Valley, and the outer-ring suburbs of LA and northern California’s East Bay are less unequal in terms of the distribution of income.
National-level data (from 2012) reveals that the top 1 percent of income earners claim just above 20 percent of the entire national income. In California for the same year, the top 0.5 percent of income earners claimed 20 percent of the entire state’s income, making California more unequal than the rest of the U.S.
Californian’s earning above $400,000 (roughly equal to the national average income level of the top 1 percent) account for 1.7 percent of California’s population, but they claimed $349 billion of the state’s total income. That’s equivalent to 30 percent of the state’s entire income.
At the other end of the spectrum in California are workers, retirees, students, and other low-income persons who claimed less than $49,000 in income in 2012. These 9.5 million people, equal to 60 percent of the state’s total population of tax filers, claimed only 17 percent of the total income pie. (See the graphs below; aggregate dollars in thousands; numbers not equal to state’s population, but instead the population of tax filers; some tax filers filed jointly; other caveats apply.)
By far the most unequal counties in California are those that encompass the deliriously wealthy cities of Silicon Valley. San Mateo County appears to be the most unequal county due to a concentration of super-high income earners in places like Atherton, Woodside and Menlo Park, alongside a cluster of very low income individuals who live mostly in places like San Bruno and South San Francisco. It’s poverty amid spectacular plenty.
Larry Ellison, who was paid $96 million in 2012, describes something very small, perhaps the reported income half of San Mateo County’s residents earned the same year. Ellison’s San Mateo County residence, in Woodside, cost $200 million to build.
In San Mateo the top 3.6 percent claimed over $18 billion in income, or 48 percent of the county’s total income pie. Meanwhile the bottom 48 percent made by with only $3.6 billion in income split among themselves. For the bottom 48 percent the mean income level was $22,000. The top 3.6 percent had a mean income of $1.5 million.
San Francisco isn’t far behind in terms of extreme income inequality. The top 2.8 percent of San Francisco’s income earners claimed 39.8 percent of the county’s total income. The bottom 52 percent made by with a collective share of just 11.3 percent of the total income, giving them a mean income of about $23,000 compared to the mean income of $1.5 million for the top 2.8 percent.
Facebook CEO Mark Zuckerberg points in the direction of his net worth. Does he live in Santa Clara County, or San Francisco? From which county does he file his personal tax return? He has houses in both counties. His income in 2012 included $770,000 in salary and bonuses from Facebook, putting him comfortably in the top 1%. Of course it’s the Facebook stock and options he’s amassed that makes him truly wealthy, therefore today he only claims $1 a year in pay.
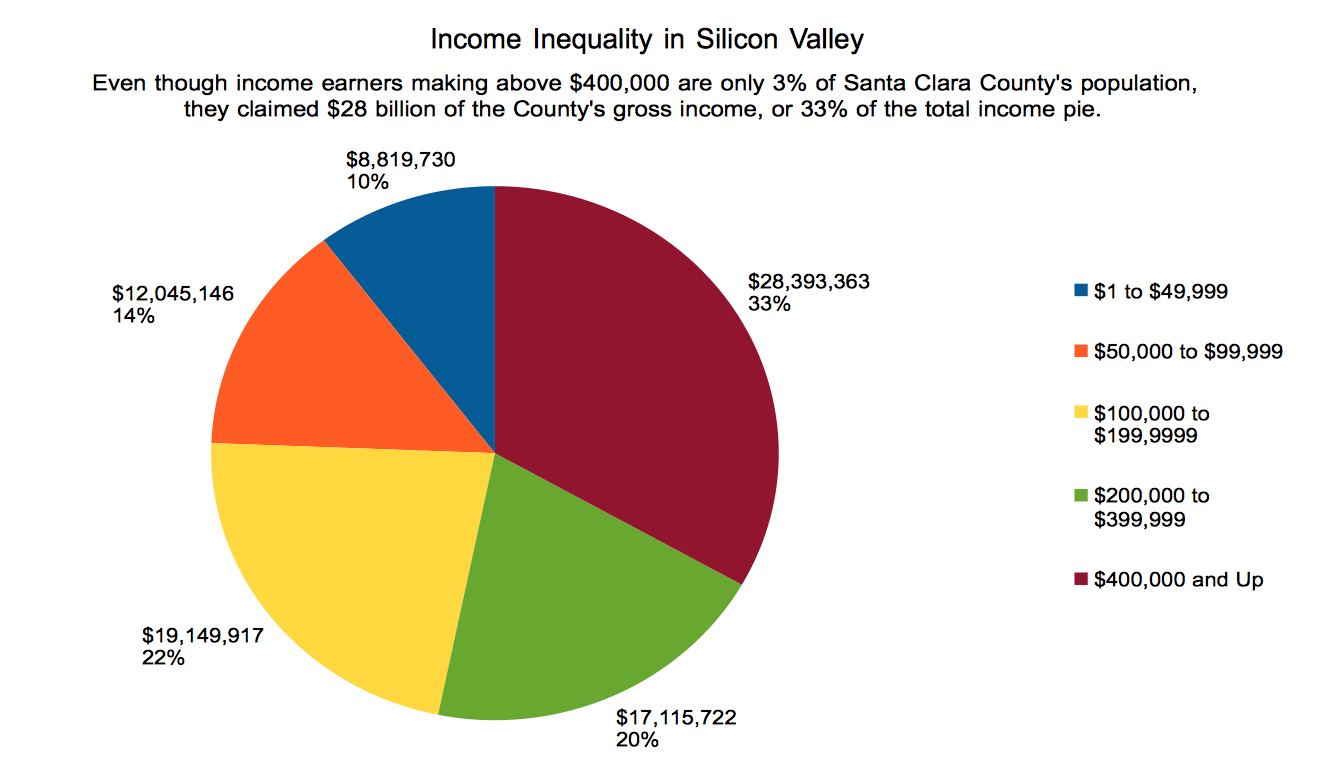
Santa Clara County is similarly riven with extreme income inequality. Those making $400,000 and up claimed 33 percent of Santa Clara County’s total income pie, even though they only accounted for 3 percent of the county’s taxpayers.
In Los Angeles and Alameda counties the income distributions look different due to several factors. First is the sheer concentration of very poor people in these counties, in numbers exceeding San Francisco and San Mateo. LA and Alameda counties also have somewhat larger middle classes that claim bigger shares of the total income pie. Even so, these counties are still dramatically unequal. In Los Angeles, for example, the top 1 percent claims $68 billion in income, equal to 27 percent of the county’s total income pie. The bottom 66 percent claims less than the top 1 percent: $56 billion, or a share of 22 percent of the total.
Other major population centers such as the Inland Empire and Fresno and Kern counties in the Central Valley appear to be less unequal in terms of income distribution. For example, in San Bernardino County the super-rich (those claiming above $400,000 a year in income) only took 5.6 percent of the total income pie. In Riverside it was 7.7 percent. In Fresno the top 0.6 percent took 13 percent of the total income pie, and in Kern it was 11.8 percent. Sacramento’s richest families in terms of income claimed 7.9 percent of the total income pie.
From the Brooklyn Eagle newspaper, Alberta Fields, widow of Henry Fields, the 26 year-old man shot and killed by the New York City Police in 1951.
On May 26, 1951 a twenty-six year old unarmed Black man was shot in the back by a New York City police officer. His name was Henry Fields, Jr. His father, Henry Sr., told newspapers that his son was a “good boy” who worked in a produce store on Osborn Street in Brownsville, deep in Brooklyn. Relatives said Henry Jr. had never been in serious trouble before. He died of the gunshot wound just blocks from his home.
The killing of Henry Fields might sound familiar. Fields was chased down by the police after committing a misdemeanor offense, and for it he was met with a sentence of capital punishment. Familiar too was the lack of consequences for the officer who shot Fields.
Fields was driving his brother’s car and had a fender-bender accident with another motorist. He fled the scene the accident, but was chased by motorists, including two officers in a patrol car. Not very far into the chase, Fields pulled over. The police said a flat tire stopped him. When Fields exited the vehicle, patrolman Samuel Applebaum, a military veteran with extensive firearms training, drew up his sights on the young man and fired a .32 caliber slug into his neck.
Fields was well known and liked in his community. As his lifeless body bled into the street, an angry crowd gathered. The police sent upwards of twenty patrol cars and more than that many cops to the scene. A local pastor was enlisted by the authorities to calm onlookers and prevent a riot.
Within twenty-four hours a call was put out to gather for a mass rally to protest the killing of Fields. Former Congressman Vito Marcantonio appealed to the District Attorney Miles McDonald that there be “immediate grand jury proceedings in the wanton killing.”
“This is the latest in a long series of police murders of innocent Negros,” wrote Marcantonio. “Police brutality is turning streets of New York into areas of official police lawlessness and terror.
One meeting to plan a political response to the killing drew over 1,600 people. Forty patrolmen and twenty-five plainclothes officers prowled around the community meeting.
Despite it being 1951, there was a grand jury investigation into Fields’ slaying. And here’s where it’s both a familiar and unfamiliar story. The events echo the recent actions of grand juries in Ferguson, Missouri and Staten Island, New York, but the inquiry into Fields’ murder also revealed a streak of independence in District Attorney Miles McDonald and his staff.
In June a Brooklyn grand jury declined to bring any charges against officer Applebaum. But rather than accept this decision, the District Attorney’s office, which had recently conducted investigations into police corruption and so knew well the problems within NYPD, including racism, lashed out at the grand jury. Assistant District Attorney William Siegel called the grand jury’s decision a “gross miscarriage of justice,” and shamed the member of the jury for acting “capriciously and contrary to the law.”
According to Siegel, there was more than enough evidence to bring the officer to trial for at least manslaughter. Siegel cited the fact that Fields was unarmed; that he was shot after committing nothing more serious than a misdemeanor; that multiple witnesses said Fields was exiting his car in an non-threatening manner when he was shot. Witnesses said the officer made no attempt to stop or apprehend Fields. He simply blew him away. In his appeal to the judge, the assistant DA also noted that officer Appelbaum’s testimony contradicted his expertise and familiarity with firearms. Appelbaum had previously dealt with armed suspects with less than lethal force, once even taking a loaded rifle from a man’s hands. Appelbaum told the grand jury that it all was an “accident.” He “involuntarily” drew his gun and pulled the trigger, and that the bullet bounced off a car and struck Fields.
For all these reasons, and surely because of protest pressure from the community for justice, the District Attorney took the unusual step of asking a judge for a second grand jury investigation into the Fields case, and the judge obliged. But the second grand jury agreed with the first, recommending no charges be brought. Here’s where the unrecognizable ends, and the story concludes with a familiar ring of a justice system beset by racial inequality. Even with a DA who actively sought an indictment of a police officer for killing an unarmed black man, an American grand jury declined to subject a cop to trial.
An article from the the San Francisco Call, October 15, 1899 describes Henry Dussen and his family, “in a tattered tent located on 16th street and Portrero avenue they shivered last night, supperless, except for a meal of potatoes, half cooked for lack of fire.” In 1899 San Francisco was home to many other impoverished families like Dussen’s, but also home to multi-millionaire railroad barons, sugar plantation masters, and bankers.
What’s the most unequal county in California? Maybe it’s Yuba. Or maybe Siskiyou. Or is it Los Angeles. Depends how you measure it.
One simple means of gauging inequality is to compare household income levels at the top of the income distribution to the bottom of the income distribution.
At the bottom of the income distribution are the very poor. Members of very poor households are more likely to have high levels of debt, and to experience unemployment and under-employment. Some of these very poor households subsist on fixed incomes from pensions or social security. Very poor households likely have a hard time paying rent and bills. They likely pay much higher percentages of their income to live in substandard housing; they send their kids to under-funded public schools; they have a difficult time obtaining health insurance; they pay more for credit and other financial services, and so on.
Then there are rich households. Rich households are more likely to live in clean and safe neighborhoods and cities; they send their kids to well-funded public and private schools; and their housing and other needs don’t consume all of their income. They can save and pass on wealth to their children.
Using reported household income data from the U.S. Census (American Community Survey, 2013 3-Year Estimates), I’ve categorized households into the following five categories by income for each county in California:
Very poor – Less than $49,999
Working class – $50,000 to $99,999
Middle class – $100,000 to $149,999
Upper-middle class – $150,000 to $199,999
Rich – $200,000 or more
You can object to how I’ve categorized and labeled different income ranges, but the point isn’t sociological perfection. This is a rough attempt to simplify some data and make some big picture comparisons regarding income inequality across California’s 58 counties.
Keep in mind that “very poor” and “rich” don’t refer to wealth for the sake of this discussion. These categories only refer to reported household income.
Also keep in mind that what I’m doing here is taking a very blunt measurement of inequality to compare counties to each other. One problem with using this census data is that everyone earning above $200,000 is lumped into one category (the one that I’m calling rich). There’s a big difference (two orders of magnitude to be exact) between earning say $200,000 and $20,000,000, and this is entirely lost in this Census data, so we have no idea what the gross incomes for each county are, and what the gross incomes of the top 1% or 5% really are compared to the rest of the population.
Even so, there’s some interesting patterns in the tables.
Below is a table that breaks down each county’s households into the five categories. The counties are then sorted by a simple measurement – the quotient of very poor households to rich households. Take for example Yuba County which has a quotient of 64 —the highest score of all counties. This means that for ever 1 rich household making above $200,000 a year in income, there are 64 households that are very poor, making less than $50,000 in yearly income. At the bottom of the table is Marin County where there are 2 poor households for every 1 rich household.
What jumps out when inequality is measured this way is that California’s Central Valley and other rural areas have big numbers of very poor households and very few rich households. By comparison the major urbanized areas have more rich households. And the six major counties of the Bay Area (Marin, San Mateo, Santa Clara, San Francisco, Contra Costa, and Alameda) all have the lowest very poor to rich household quotients.
Keep in mind that this doesn’t mean that the Bay Area is without very poor households. Alameda County, for example, has about 200,000 very poor households compared to 58,000 rich households, a quotient of 3.4. Yuba County, at the other end of the table, has only 13,600 very poor households even though it’s quotient of very poor to rich households is much higher.
If we re-sort the table by a different metric, the percent of poor households to the total number of all households, then Siskiyou County jumps to the top of the table. 63 percent of households in Siskiyou County are very poor. Again at the other end of the table are the six population centers of the Bay Area, with relatively low percentages of very poor households, ranging from 28 percent in San Mateo to 37 percent in San Francisco.
A final way to look at these numbers is to simply see which counties are home to largest sheer numbers of very poor households and rich households. Here it’s no contest. Los Angeles County is home to about one in every three very poor households. LA is also home to about one in every five rich households. Not surprisingly, this table largely follows the general population rankings of California’s counties.
So what’s the most unequal county in California? Well it’s probably not best to use this type of Census data to figure that out. The above tables point more toward concentrations of low income and high income households, but because the data doesn’t measure the actual amounts of income being earned (especially top incomes) it’s impossible to say just how unequal these places really are.
I’ll try to zero in closer to an answer in a subsequent blog post.
The city of Piedmont is one of the wealthiest and most exclusive communities in California, but per state law, Piedmont is required to demonstrate that it’s regulations do not block the construction of a “fair share” of new housing, including affordable housing. This doesn’t mean that Piedmont is required to build new housing. However, it does require the city to demonstrate that its municipal rules don’t impede new development.
Affordable housing is a big part of the state’s law that requires cities to show how they are creating opportunities for developers to build new housing units. Lots of cities are eager to attract affordable housing development, including Oakland and San Jose. Piedmont, however, was founded as a wealthy enclave, and has built itself out physically, and politically, to exclude the construction of affordable housing within its limits.
So it’s not surprising to read in Piedmont’s Housing Element (a document that spells out how the city plans to create opportunities for building a “fair share” of housing, including affordable housing) that Piedmont’s only contribution to creating more affordable housing is to add servants’ quarters to some of the mansions that dot it’s hilly landscape.
According to Piedmont’s Planning Commission, the city has a very small number of rental housing units, only 50 apartments. All of them are crammed along Linda Avenue on the Oakland border. Piedmont has only 50 vacant lots upon which to build new housing, and many of these sites are unfit for construction of any large multi-unit structures. Piedmont was zoned decades ago to be a community of homogenous single family homes with large yards and long driveways. The only variation really was in the size of the lots, starting with large houses surrounded by generously proportioned yards up to the multi-acre estates along Sea View Avenue where every residence has its own private tennis court and pool and English garden fit for long walks under rows of redwoods and oaks. Piedmont’s city charter requires a referendum of all voters to change zoning in any area of the city from its current single family status to a multi-family zone that could accommodate apartment construction, or renovation of existing mansions into multi-unit buildings. In other words, this ain’t gonna happen.
The result is that Piedmont isn’t likely to build affordable housing, even though it’s required to demonstrate that developers have the opportunity to build affordable housing that would contribute a “fair share” to the Bay Area’s needs. The solution Piedmont’s government has come up with to build new and affordable housing is to encourage the addition of servants’ quarters—small studios and apartments added to the basements or attics above the garages of mansions. In fact, many homes in Piedmont were originally built with servants’ quarters for butlers, maids, nannies, gardeners, and other helpers. But having help fell out of fashion after the 1960s, so lots of these quarters were turned into dens or guest rooms. Piedmont’s planners hope that homeowners will take these spaces in their houses and re-convert them into rental units.
“Given the lack of vacant and redevelopable land in the City, Piedmont has historically explored other ways to meet future affordable housing needs,” explains the city’s Housing Element. “Since the 1990s, the City has found that the most effective approach is to actively encourage the production of second units.”
Here’s a more detailed description excerpted from Piedmont’s Housing Element explaining what these second units are:
“The City of Piedmont has a long tradition of allowing second unit housing. Many of these units were initially created as living quarters for domestic employees. Today, second units in Piedmont provide housing for professionals, seniors, caregivers, child care employees, relatives, and young adults entering the housing market, among others. In some cases, elderly Piedmont homeowners have moved in to second units on their own properties in order to retain ownership and have a source of retirement income. Given the single family character of the city and the absence of land available for new development, second units are the most practical and prevalent form of affordable housing in the city today.”
The process by which the East Bay funds transportation infrastructure and transit services is similar to industrial sausage making. All kinds of ingredients are ground into the initiatives that voters must either approve or deny in their entirety. Almost every voter will, if they read the long list of transportation projects in the expenditure plan attached to these massive regional sales tax initiatives, find something they don’t want to see built. But for a transportation package to be approved, 66.67 percent of voters have to feel like they’re getting more of what they want compared to what they don’t. Alternatively, it helps if voters simply don’t read the complete list of ingredients. When you notice that 10 percent of your hot dog is made of rat tails, you tend to throw it all out, even if the other 90 percent is organic apples and grass-fed beef.
It’s a dysfunctional process because it often results in voters striking down much needed transportation funding over relatively small objections in the big list of projects.
If passed, Measure BB will raise Alameda County’s sales tax by half a cent, creating a total 1 cent sales tax dedicated to funding transportation capital projects and services, just like Measure B1 would have done in 2012.
But unlike Measure B1 from 2012, Measure BB sunsets the half cent tax increase after 30 years, instead of continuing the tax forever. Measure BB also eliminates a poorly-planned and expensive rail project that would have run across the Dunbarton Bridge in the South Bay, replacing it with bus services that will likely serve more riders at lower cost.
Measure BB is good, and you should vote for it. Most of what Measure BB will fund is desperately needed. It’s better for the climate, and more equitable because it expands transit services that lower income communities, youths, and seniors, rely one.
Unfortunately there’s still rat meat in the sausage, and you can’t pick it out as you eat. If you want the money for bikes, buses, youths and seniors, you’ve gotta swallow the rodent flesh too.
Measure BB will set aside 10 percent, or $749 million in total revenue to fund BART. Some of this money will go toward improving the existing BART system, which is without a doubt another good reason to vote for Measure BB. However most of the BART money will be spent expanding the BART system out into Livermore and down through Fremont toward San Jose.
“BART has multi-billion dollar shortfalls to maintain their existing system,” the group explained in its analysis of Measure BB released in June. “These shortfalls are already causing maintenance and capacity problems. If BART does not refocus its attention on maintaining the existing system, the problems will get worse, endanger rider and worker safety, slow down the trains, make it even more cramped, and reduce the number of people BART can carry at rush hour.”
This all might lead to another BART strike, to say nothing of the crowding on trains, broken escalators, long delays, and numerous other problems.
“The total cost of the BART extension to Livermore is 3.2 billion, of which $400 million is a down payment,” said Cauthen. “It’s a total waste of money to run a bart line out to a low density area.”
Cauthen calls other recently built BART projects like the Oakland Airport Connector “boondoggles,” and said the agency should learn from past mistakes rather than continuing to waste resources.
“The legacy here is one of wasting money on these transportation projects caused by politicians who simply don’t stop, gather professionals, study the options, and pick the best ones,” complained Cauthen.
Economist Arthur Pigou.
But there’s one other problem with Measure BB besides what gets funded. Measure BB is a regressive tax to finance transportation. To paraphrase a famous economist, it’s best to tax bad things and use that money to pay for good things that broadly benefit society. Bad things are those that pollute, like burning gasoline and taking up road space in a private automobile that causes wear and tear on streets and endangers pedestrians and bicyclists.
And if ever there was a good thing in Alameda County, especially in revenue-starved cities like Oakland, it’s consumer spending at local retail stores. Retail sales are a sign of job creation, and the circulation of money in the local economy. The regressive impact of taxing retail spending is well known. Sales taxes force low-income households to pay a higher share of their total income than affluent households.
So why use sales taxes to subsidize transportation and transit? And can’t we find a more equitable and robust source of funding?
“That’s the fundamental question that every transpiration agency is grappling with right now,” said Tess Lengyel, Deputy Director of Planning and Policy at the Alameda County Transportation Commission. “What used to be a silver bullet, the gas tax, it no longer works.”
Self help has become increasingly necessary as federal and state gas tax revenues dwindle.
Lengyel said, however, that Measure BB shouldn’t be characterized as a regressive a tax.
“You have to look at what this pays for and who benefits,” said Lengyel. “A lot of people called these sales tax measures regressive before because the expenditures had a lot to do with highways, and the people paying the tax were paying for something they mostly weren’t using.”
Now, said Lengyel, a fair share of the revenues that will be raised by Measure BB will fund transportation projects that benefit lower income workers, urban residents, bicyclists, pedestrians, bus riders, and others who will pay a big share the tax.
Even so, the land values created by transportation infrastructure and transit services are a windfall to property owners who pay low taxes since 1978’s Proposition 13. Meanwhile sales tax measures have come to subsidize a growing percentage of all transportation expenditures in the state. At the same time politicians have found it popular to cut gas taxes and vehicle registration fees, cratering transportation funding while doing nothing to address climate change. And they haven’t replaced these taxes fully with new revenue sources, leaving infrastructure in disrepair.
As for more equitable revenue streams to pay for the transportation projects we need?
“The state has been looking at vehicle registration fee, and a vehicle miles traveled tax,” said Lengyel. She added that cap and trade funds may be used to fund transit and transportation projects also. But to build a bridge from here to there, it looks like we’re stuck with the self-help retail sales tax.
There are many ways to think about a city. One is that the city is a place. Cities are built environments with clear geographical boundaries. Each city is embedded in a region and connected to other cities-as-places. And people, goods, and capital flow between cities, accumulating in some and draining from others. This conception of the city is cadastral. It’s mapped out and made legible as a market through the measurement of physical boundaries and values like home prices, tax rates, and school rankings. As these values rise and fall, so to do the fortunes of the city.
A different way to conceive of a city is that it is a people. Instead of seeing buildings and streets and spaces all linked together in a specific legal and economic schema, this perspective instead finds the city in the people who reside there. The city is a sum of their social relationships, their cultures, institutions. This city is set, for certain, in a particular place, but it’s made a city by the ties of kinship, friendship, and communal obligations that enliven the geography. The community makes the city, and so if the community prospers, so does the city. If the people suffer, so does the city.
In Oakland, California these two conceptions of the city are opposed to one another. And for well over a decade the city-as-a-place has been erasing the city-as-a-people.
It began sometime in the 1990s. After decades of disinvestment, de-industrialization, and the flight of affluent households to exurbia—a process that made Oakland what geographer Richard Walker called a “dark star in an expanding universe,”—the tide of capital suddenly, and at first imperceptibly reversed. Real estate investors began pouring money back into Oakland, often benefiting from city and redevelopment agency subsidies, tax breaks, land swaps, and municipal bonds. Young and affluent white collar workers started moving into apartments and houses around the eastern edge of Lake Merritt, into the downtown, and Jack London Square, and North Oakland. By 1999, when Jerry Brown took over as mayor, the rise of Oakland-as-a-place had already started. But Brown’s 10K Plan accelerated the process.
Inherently a city-as-a-place initiative, the 10K Plan envisioned Oakland, or to be more precise a small slice of downtown Oakland, as a blank slate upon which to inscribe enough new units of housing, mostly condos and apartments, as well as retail stores, theaters, restaurants and all the other trappings of the ideal contemporary urban vitalism, to attract 10,000 new residents. The point was that Oakland’s government would partner with real estate capitalists to build up the city-as-a-place. In turn, this place would conjure a new assemblage of people, drawing in especially the coveted young, monied, hip, consumers seeking an urban alternative to San Francisco.
In an excerpt from Stephen Talbot’s 2001 documentary The Celebrity and the City, Jerry Brown explained the origins of his plan to re-populate downtown Oakland by remaking its places and spaces: “People would say, ‘well why can’t we shop in downtown Oakland? Why do we have I have to go to Walnut Creek? Why do I have to go to San Francisco?’ So that germinated the idea, let’s restore downtown Oakland,” said Brown.
To do so Brown and the real estate entrepreneurs gathered around him understood that they couldn’t just open up retail stores downtown. They had to bring a new and different category of people to Oakland. They weren’t going to build up Oakland for people already living in its borders. That would require tackling big social and economic problems like poverty, unemployment, housing and food insecurity, and institutional racism in the schools and criminal justice system.
Perhaps they had given up on such battles long ago. Brown certainly began abandoning progressive political economy in the late 1970s. He came to accept the straightjacket of neoliberal urbanism that the tax rebellions and withdrawal of federal aid to cities imposed. Since then it has been much easier to provide grants and credits and subsidies for the benefit of private real estate developers than it has been to institute policies that boost the incomes and opportunities for low-income city dwellers.
“We do want capital flowing into Oakland,” Brown said in 2001. He complained, however, that the 10K plan was being stalled by a “negative cheering section” that, “says that anything that happens, that’s going to disrupt something.”
“We’re going to be displaced,” Brown said, repeating the concerns he was hearing from Oaklanders. “They got a name for it: gentrification,” said Brown dismissively.
In the same documentary Brown’s mayoral campaign treasurer and friend, real estate developer John Protopappas is filmed standing outside a live-work loft project in West Oakland teasing a black man on a bicycle who is pulling a shopping cart filled with bottles and cans. “Come on, you gotta move in,” shouts Protopappas. “I don’t think he’ll be moving in,” he then says to the cameraman.
Oakland circa 1999 absolutely lacked “shoppers” downtown. Its built environment was dominated by office buildings filled with the employees of big corporations and law firms during the work week, but come 5pm and weekends the downtown would die as these employees escaped in their cars and via BART back over the hill to the East Bay suburbs. Downtown Oakland was decidedly not hip.
The people actually living downtown, the Oaklanders who weren’t following Brown’s desire of shopping, who weren’t economically capable of buying one of Protopappas’s condos, were predominantly Black, Latino and Asian, with many of the latter two groups made up of first generation immigrants. The low-incomes and high poverty rates afflicting this community meant that without any kind of intervention to empower them economically, they would not be the ones shopping at the new GAP clothing store Brown and his wife (a lawyer for the GAP) were so excited to open on Broadway. Oakland’s existing residents, at least those living in the flatlands, wouldn’t be leasing new apartments opening in Jack London Square, Temescal, and the Uptown.
Instead many of them were displaced through the process of “Jerryfication,” as critics called it. Many more stayed, and have since endured an influx of new residents who have bid up the prices of real estate, making survival in Oakland difficult in new ways. Whereas once life was made difficult by Oakland’s existence outside of key circuits of capital and employment, now it is Oakland’s incorporation into these circuits that is driving up prices and dispossessing long-time residents of their homes and communities.
Between 2000 and 2013 Oakland lost 27 percent of its Black population, dropping to a low of 103,000. In that same time the city’s white population grew by the same percent, rising from 125,000 to 160,000. In the Census Tract that encompasses the Uptown District the Black population grew by 9 percent between 2000 and 2012. But the white population expanded by 74 percent, from 400 to 700 residents.
The success of Brown’s 10K Plan is evident in the numbers of affluent individuals who have moved into downtown Oakland and spilled over in North Oakland and around Lake Merritt. It’s also evident in the restaurant boom which has become a favorite story for culinary magazines to cover over and over again. And since Brown showed that Oakland could ditch its no-there-there and become a somewhere destination, each successive mayor and city council has sought to further advance the vision of Oakland-as-a-place.
Over the last decade, influenced by Oakland’s real estate entrepreneurs, the city government borrowed from the capital market to fund “quality of life” improvements, including a multi-million dollar makeover of Lake Merritt, the estuary and park around which home and rental prices have exploded upward in recent years. New bike lanes along MacArthur Boulevard and 40th Street connect gentrifying neighborhoods to 3rd wave coffee shops, $10 a bowl mac and cheese diners, and BART stations that shuttle a big percentage of newcomers to their downtown San Francisco office jobs.
The process has now hit full stride. Notwithstanding a recession, whole sections of Oakland are soon to be scraped clear of existing buildings and streets and rebuilt into simulacra of San Francisco’s SOMA or the nearby boomlet of Emeryville. The most ambitious is the West Oakland Specific Plan, or WOSP. Pronounced “wasp,” the plan calls for adding thousands of new homes, 85 percent of them market-rate condos and apartments, that will sponge up spillover from San Francisco’s extremely expensive housing market.
There’s also the Oak to 9th project, now being called Brooklyn Basin, a ground-up master development with 3,100 housing units that will be set on two spits of land protruding into the Oakland estuary. Years ago Oakland mayor Jean Quan was a leader in the radical student movement, an organizer of the Third World Liberation Front, and a self-avowed Maoist revolutionary. Now Quan spends her time recruiting other former Maoists—Chinese billionaire capitalists—to invest in Oakland real estate.
Screenshot from the web site of Zarsion-OHP 1, LLC, developer of the Brooklyn Basin project, depicting the diversity of residents the new master-planned community will attract.
But like the WOSP, Brooklyn Basin is being built from the ground up to attract a diverse mix of residents within certain parameters. It’s bounded diversity; restricted to people whose income and cultural capital exceeds that of the city’s current majority. Brooklyn Basin is a plan to develop Oakland as a place, not as a people. Although the 2006 development agreement between Oakland and Ghielmetti required building affordable housing on-site, the total was only 15 percent of the project’s 3,100 units, or about 465 homes. This proportion totally reverses the actual ratio of above median income households to below median income households that currently live in the neighborhoods surrounding Brooklyn Basin. One in every three families living next to the site where Brooklyn Basin’s towers will soon rise is living below the poverty line, and the neighborhood’s median family income is $37,000, about 22 percent below the median household income for the entire city.
Perhaps some Oaklanders from the working class half of the city will find jobs building Brooklyn Basin. Or perhaps they’ll find jobs in the stores and restaurants that open there. But economic progress along these lines is an afterthought, and it’s also not necessarily progress. What will these jobs pay? Will the workers be able to keep up with the rising rents and other cost of living increases that come when a city truly becomes a destination for wealthy Chinese condo owners and Silicon Valley executives and lawyers buying second homes along Oakland’s waterfront?
Recent mayors and city council members have shown, in their efforts to transform Oakland, that they can conceive of the city as a people. Progressive public policies like a living wage ordinance, local hire requirements for city contracts, and most recently a majority on the city council supporting a significant city-wide minimum wage increase are among the most obvious measures taken to “lift up Oakland.”
But the city-as-a-place, as an investment platform upon which to assemble objects and spaces of consumptive desire, has long dominated the thinking inside One Frank Ogawa Plaza, City Hall. In their e-mail signatures, Oakland politicians and city staff are in the habit of including a link to a 2012 New York Times article ranking Oakland the #5 top place to visit in the world. The city that’s being made right now is increasingly incompatible with the city that is. The Oakland as-a-place being built is too expensive for the Oakland-as-a-people who live here. Where will they go? Likely further into East Oakland, the last section of the city that because of its geographic isolation from the downtown, and because of its deeply entrenched poverty, is not a destination, is not drawing in the same kind of speculative capital and middle class home buyers. To Richmond, Vallejo, Antioch and Pittsburg, and other non-destination cities further up and off the BART lines and under the shadows of refineries and power plants the displaced will move.
Next week the Oakland city council’s community and economic development committee will likely green light a 250 to possibly 400-unit residential building at 2100 Telegraph Avenue. The developer, Alan Dones, has already built offices and apartments in Oakland’s Uptown. Like most other big real estate projects requiring city assistance (Dones’s proposal is to build atop a city-owned parking garage) the city has significant say in what gets built, but the project’s plan only calls for 15 percent of the units to be affordable to moderate and low-income households.
And what does affordable even mean? Per Oakland’s official Housing Element, a state mandated plan, this would mean apartments that a single person earning $45,100, or a three person households earning $58,000, can afford. These are the official definitions of “low income” in Oakland. Moderate income is defined as a single person earning $74,950, and a three person household with an income of $96,350.
No one who has ever set foot on the corner of Telegraph Avenue and 21st Street, where Dones’s project will be built, could possibly think for a second that these income levels approximate those of the neighborhood’s current residents. The reality of life in Oakland’s flatlands is that many households earn below $25,000 a year, and they must spread these meager dollars far to feed many mouths, pay ever-increasing rents, and pay for a highly regressive set of municipal services, from trash to transit. Even the affordable units, it appears, will be priced to attract outsiders. Uptown Oakland is in fact one of the most impoverished urban zones in California. The poverty rate in the surrounding Census Tract is 44 percent. Over half the neighborhood’s households earn less than $25,000 a year.
Ultimately the problem isn’t that too much market-rate housing is being built. It’s that too little affordable housing is being added to the city’s total stock. The authors of Oakland’s Housing Element admitted as much when they wrote the following:
“the City encountered some difficulty in achieving very low-, low- and moderate-income housing production goals in the 2007-2014 planning period. The increasing gap between housing costs that very low-income household can afford and the cost of producing very low-income housing units, combined with the limited amount of subsidies to produce such housing, continues to challenge the City’s ability to meet ABAG’s regional housing allocation for the City for these households.”
What’s getting built isn’t designed to benefit the people of Oakland who are already here and need something better. More so, there’s too much time and energy spent by Oakland’s government greasing the gears of real estate development at any cost, and not enough time crafting policies to make the city an economically just community. The result is what many of the people of Oakland feel today; their city is becoming unaffordable. Evictions are increasing in areas like North and West Oakland where huge demographic shifts are taking place. The city appears (although it isn’t) powerless to create good paying jobs for its existing residents, but it can and soon will create a surplus of expensive real estate. It’s all the result of seeing and treating Oakland as a place, and not as a people.
A coalition of UC students, faculty, staff and alumni have pressed the UC regents to divest from fossil fuel stocks and bonds. On Tuesday, the UC’s CIO released a recommendation that regents not pursue divestment, and instead develop “a framework for the management of environmental, social , and governance considerations.”
UC’s CIO, Jagdeep Singh Bachher was recently hired by the regents to run the university’s finances, more than $90 billion in funds. Bachher previously helped run the Alberta Investment Management Corporation (AIMCo), the sovereign wealth fund of Alberta, Canada. While helping pick investments for AIMCo, Bachher steered the province’s money into coal, oil, and gas companies and projects in North America, China and beyond. He also prioritized renewable energy and clean tech investments. But nothing in his record indicates that he would support divestment from fossil fuel companies. Instead it appears that Bachher sees clean tech as simply one part of a diversified investment portfolio which includes fossil fuels.
AIMCo’s stock holdings, disclosed in this SEC filing, show that the Canadian province’s savings are concentrated in oil and gas companies. About $1.8 billion of the total $8.9 billion in stock owned by AIMCo, roughly 20% of the total, is in an oil, gas, or coal company.
AIMCo’s single largest stock investment is a $374 million stake in Bonanza Creek Energy, an oil and gas company that utilizes fracking techniques in North American oil patches.
AIMCo’s second and third biggest investment positions in publicly traded stocks are Canadian Natural Resources and Suncor Energy, two Canadian oil companies that are excavating the tar sands, arguably the most environmentally destructive energy projects in the world.
Bachher also portrayed these investments as opportunities to develop “clean energy,” but it’s clean energy built atop a fossil fuel base.
For example, Bachher singled out AIMCo’s investment in Calera, a California company that aims to capture CO2 emissions and use them to manufacture materials like cement. To leverage China’s five year economic plan, which includes contracting with Peabody Energy to build massive coal-fired power plants, Bachher hopes that companies like Calera will capitalize from the expansion of coal fired energy to utilize some CO2 emissions to create “green cement.”
Peabody Energy, one of the largest coal companies in the world, had a voice in UC’s recent deliberations around the question of whether or not to divest university funds from fossil fuel companies. As I reported in this week’s East Bay Express, Gregory Boyce, Peabody’s CEO, was invited by Bachher to speak to the UC regents task force considering the question of divestment.
Attorneys employed by the Stroock Stroock & Lavan law firm often are hired after careers in state and federal law enforcement and regulatory agencies like the Securities & Exchange Commission and California Department of Justice.
In a story this week for the East Bay Express I detailed how Benjamin Diehl, a Supervising Deputy Attorney General for the California Department of Justice, quit his post last year, and immediately joined a private law firm that represents many of the same financial corporations he was previously tasked with investigating and prosecuting.
By switching sides, by going from the DOJ’s mortgage fraud strike force, and consumer protection section, to Stroock Stroock & Lavan’s Government Relations group—Stroock is one of the most aggressive defense firms backing banks, mortgage lenders and servicers, and credit card companies in disputes against consumers and state law enforcement—Mr. Diehl is walking a fine line with respect to the law and professional ethics. Of course there’s nothing wrong with a lawyer taking a new job, and shifting gears in their career. But when a government lawyer contemplates switching sides, they must navigate a complex set of ethical and legal questions so that they don’t do harm to the public.
Public perception in recent years is that top federal lawyers in the U.S. DOJ, the Securities and Exchange Commission, and other enforcement agencies are simply cashing in on their connections and knowledge, and perhaps even going soft on Wall Street while in government, all in order to secure lucrative post-government jobs defending and lobbying for the financial sector. The revolving door between Covington & Burling and the DOJ has gotten a lot of press, for example. Much of the public has lost faith in the effectiveness of the justice system.
I inquired with Stroock as to what sort of systems and procedures the firm has in place to ensure that Mr. Diehl will be separated and recused from cases that he might have worked on as a member of the California Attorney General’s staff, and how the firm will ensure he does not breach his duty of confidentiality to the State of California with respect to detailed legal information he surely has about California’s prosecution strategies, but the law firm declined to comment. I also inquired with the California DOJ about Diehl’s exit, but received no response.
I asked in part because of the timing of Mr. Diehl’s departure from the DOJ and his hiring by Stroock. Mr. Diehl announced his resignation from the DOJ in October, 2013 and joined Stroock as special counsel in November of 2013. But e-mails I obtained indicate that he was having private conversations with Stroock attorneys at least as early as April of 2013, a period in which he presumably had significant influence over multiple financial fraud and consumer protection investigations and lawsuits, including enforcement actions directed against clients of Stroock. The subject of the conversations between Diehl and the Stroock partners isn’t clear, but you can read the email exchanges yourself.
Diehl was a frequent speaker and attendee at financial industry conferences put on by the American Conference Institute, and a legal education group called the Practicing Law Institute. These conferences are geared toward educating in-house counsel and defense firms that work for financial corporations, many of which specialize in defending banks from consumer protection lawsuits. Attending these conferences, alongside Mr. Diehl, were several partners of the Stroock Stroock & Lavan law firm.
Attorneys are supposed to zealously represent their clients. They have a duty of loyalty and confidentiality to their current and past clients. Attorneys shouldn’t allow the interests of any other party, or their own personal interests, including future career opportunities they’re hoping to pursue, to interfere with the duties of loyalty and confidentiality they owe a client. And the information clients share with their lawyers, as well as information attorneys generate through investigation, and work products such as prosecution and defense strategies, should be maintained in confidentiality under most circumstances. Sharing this information with oppositional parties is especially problematic.
If the information a former government attorney shares is general in nature, that is, if it isn’t confidential information related to specific investigations or lawsuits, or specific government regulatory and litigation strategies, then it’s usually considered legal and ethical for a lawyer to share with new clients.
Attorneys employed by the State of California to represent the interest of the state’s offices, agencies, and ultimately the people of California, must follow the same rules as other government servants. The Political Reform Act puts several restrictions on state attorneys who leave government employment and go to work for the private sector. Specifically, California law bars government lawyers from switching sides and representing new clients in proceedings (court cases, negotiations, administrative hearings, etc.) that they previously worked on as government attorneys. This is a very specific prohibition with lifetime duration.
Government attorneys are also prohibited from making decisions that might materially affect a person or company with whom they’re negotiating with for a job. The law’s exact wording is:
“No public official shall make, participate in making, or use his or her official position to influence, any governmental decision directly relating to any person with whom he or she is negotiating, or has any arrangement concerning, prospective employment.”
Of course the exactitude of these laws leaves plenty of big loopholes. And the secrecy that lawyers can easily maintain, including government lawyers whose records, for the most part, are not subject to disclosure under the California Public Records Act, makes it hard for the public to keep tabs on what crucial decisions an attorney is making, and how they might relate to post-government employment pursuits.
Urban Shield, a law enforcement conference that includes SWAT competitions, training exercises, briefings, and a large vendors show, is underway again in Oakland this year. The downtown Marriott hotel and conference center is packed with police officers and police-industrial contractors selling everything from machine guns to drones. Alyssa Figueroa of Alternet has a good story about Urban Shield and the protests against it this year, and Ali Winston and I wrote about the event last year.
I briefly walked through the conference this morning. What’s different this year is the size of the event. It feels bigger, and attendees said they thought there were more participants and vendors.
Here’s some photos from the vendors show.
Guns are a big deal at Urban Shield. Salesmen from Sig Sauer chat about rifles and pistols. Sig Sauer’s gun factory is located in New Hampshire.
A company named Execushield which claims to have been founded on September 11, 2001 shows off a video of its paramilitary security forces operating in Columbia. Based in San Francisco, Execushield specializes in providing security to high net worth individuals and Fortune 500 companies. A salesman manning Execushield’s booth said he could not talk specifics about clients.
Members of the Brazilian Police are attending Urban Shield this year. Here the Brazilians get a demonstration of a portable explosives detection device.
Drones are still in demand among law enforcement agencies, even though there has been significant public backlash. Here representatives of HaloDrop show off their drone aircraft which the company rents out as a service to government agencies.
The .50 caliber AW50, manufactured by Accuracy International, a British weapons maker that specializes in military sniper rifles. Mile High Shooting Accessories, a vendor attending Urban Shield and distributing these weapons, says the rifles are increasingly popular with U.S. police agencies. The Alameda County Sheriff has bought several of these AW50s (for about $5,000 a piece), and the Livermore police have bought other models made by Accuracy International.
A sales rep for Mile High Shooting Accessories of Colorado shows off various models of Accuracy International’s sniper rifles to Bay Area police.
Participating in this year’s Urban Shield tactical competitions, the U.S. Marines.
Arizona gun maker Patriot Ordnance Factory shows off its weapons at Urban Shield. Patriot sells weapons to the California Highway Patrol.
Patriot Ordnance Factory’s weapons include the words “God Bless America” inscribed below the chamber.